
Of all the new Microsoft Fabric announcements at Ignite 2024, one that I’m really excited about is the public preview of Fabric Mirroring for SQL Managed Instance. This brings together two of my favourite technologies I’ve been working with over the past few months and allows customers to really make the most of their investment in Azure SQL Managed Instance (SQL MI) and Fabric.
Introduction to Mirroring
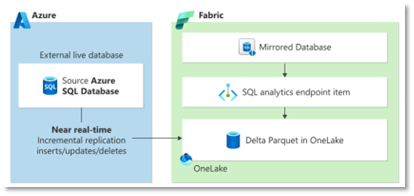
Fabric mirroring is already available for Azure SQL DB (which has just been announced as GA). This feature brings similar functionality to customers who have modernised their SQL Server data platform onto SQL MI. Mirroring provides an easy way to replicate data into Fabric without having to create complex ETL (Extract Transform Load) processes. Data is continuously replicated directly into OneLake, converting the data into Delta Parquet files, allowing the data to be used by other services in Fabric, such as running analytics with Spark, and executing notebooks to perform transformations.
A SQL analytics endpoint is also created to allow the data to be queried using T-SQL and create views, stored procedures and functions. A default semantic model allows Power BI reports and other tools to visualize and explore the data.
Pre-requisites
This blog will walk you through getting started with Fabric mirroring for SQL MI. All service tiers are supported (including Next-Gen General Purpose) and the SQL MI can be a single instance or a member of an instance pool. The system assigned managed identity (SAMI) should be enabled as should the Allow service principals to use Power BI APIs Fabric Power BI setting.
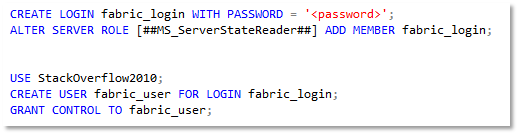
On my SQL MI, I created a login and granted permissions in the databases I planned to mirror:
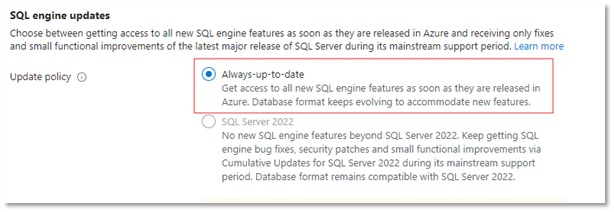
The update policy of the SQL MI should be set to Always up to date and the public endpoint should be enabled and Azure services allowed to connect to it:
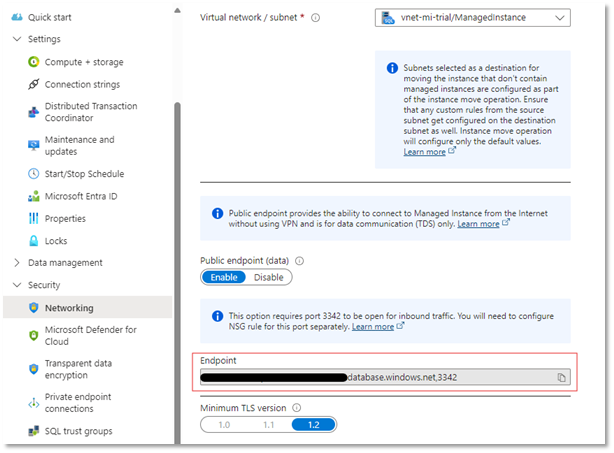
Take note of the public endpoint highlighted above as you’ll need this to set up the connection in Fabric.
Mirroring Walkthrough
Now that the prerequisites on the SQL MI are in place, we can set up mirroring and let the magic begin! In your workspace, create a new Fabric item and search for “mirrored”. This will show the different mirroring sources available. Select Mirrored Azure SQL Managed Instance database (preview):
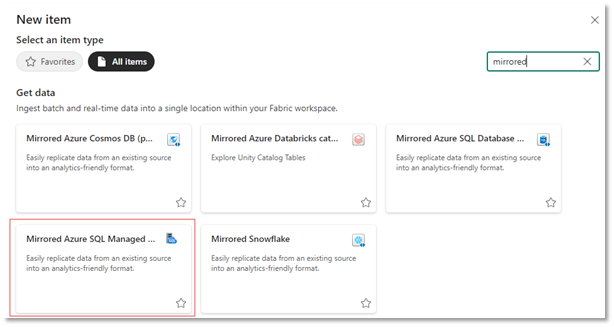
We need to connect to the SQL MI by selecting Azure SQL Managed Instance as the source:
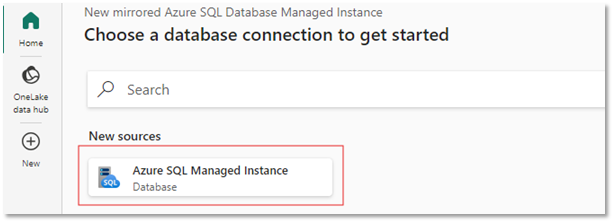
If you select New Connection, the following screen will be displayed. You need to enter the public endpoint copied in the step above and the other relevant details. I’ve used Basic authentication, so enter the login details you created on the SQL MI earlier:
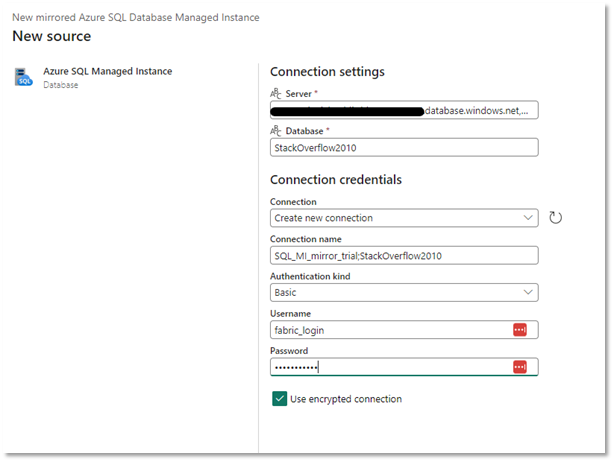
Hit Connect and you’ll then see the following screen. If any tables are ineligible for mirroring (more on this later) you’ll see warnings or errors beside the tables. All my tables are good to go, so I’ve selected them all. There’s also an option here to automatically add any new tables created in the future.
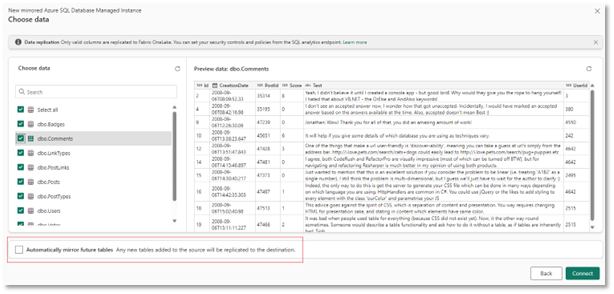
You then specify the destination name, and select Create mirrored database to complete the setup:
Once completed, you’ll see the mirrored database, the SQL analytics endpoint and the default semantic model created in your workspace.
Click on the database name, then Monitor replication to see the progress of each table:

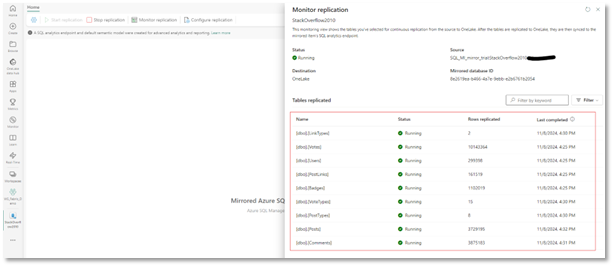
That’s all there is to it! You’ll see a status of Running to show that replication is currently copying data into OneLake and the Last completed date shows when the table was last checked for changes.
Querying the Data
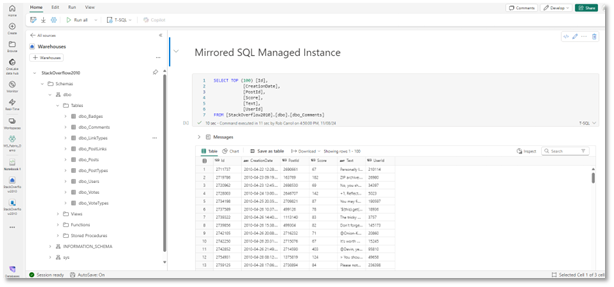
Now that the data is in Fabric, we can query it using the SQL analytics endpoint shown below:
Limitations and Considerations
As with Azure SQL DB, there are some limitations to be aware of. I’ve already mentioned the update policy should be Always up to date and that the public endpoint needs to be enabled. Mirroring also can’t be used if the database has Change Data Capture (CDC) or Transactional Replication enabled. The maximum number of tables is also set to 500 tables per database. Mirroring is not supported across Microsoft Entra tenants, and tables currently need to have a primary key. A full list of limitations can be found here: Limitations and behaviours for Fabric mirrored databases from Azure SQL Database (Preview) – Microsoft Fabric | Microsoft Learn
Conclusion
Mirroring provides an easy way to bring your data into Fabric. It’s simple to set up and will replicate changes in near-real time. There are no ingress fees or additional costs for storing mirrored data in Fabric (you only pay for the compute used querying the data) making it a fantastic option for getting the best out of your SQL Managed Instances and Microsoft Fabric.